


การลงทุน
บัญชีหุ้นกู้อีซี่ดี
บริการรับฝากหุ้นกู้แบบไร้ใบ
ไม่ต้องเก็บรักษาใบหุ้นกู้อีกต่อไป
บนแอป SCB EASY
ผลการค้นหา "{{keyword}}" ไม่ปรากฎแต่อย่างใด
การใช้และการจัดการคุกกี้
ธนาคารมีการใช้เทคโนโลยี เช่น คุกกี้ (cookies) และเทคโนโลยีที่คล้ายคลึงกันบนเว็บไซต์ของธนาคาร เพื่อสร้างประสบการณ์การใช้งานเว็บไซต์ของท่านให้ดียิ่งขึ้น โปรดอ่านรายละเอียดเพิ่มเติมที่ นโยบายการใช้คุกกี้ของธนาคาร
"Typhoon" โมเดลภาษาไทยขนาดใหญ่ โดยคนไทย เพื่อคนไทย จาก SCB 10X

วันนี้ “Typhoon” (ไต้ฝุ่น) ที่เรารู้จัก จะไม่ใช่แค่ชื่อของพายุเท่านั้น แต่ยังเป็นชื่อของ Open Source AI ที่เป็นโมเดลภาษาไทยขนาดใหญ่ (Large Language Model หรือ LLM) มีประสิทธิภาพโดดเด่นในกลุ่มโมเดลภาษาไทยที่มีอยู่ในตลาดในปัจจุบันนี้ โดย Typhoon ลูกนี้จะเข้ามาช่วยขับเคลื่อนวงการเทคโนโลยี AI ของไทยให้มีโมเดลภาษาขนาดใหญ่ที่พัฒนาขึ้นสำหรับภาษาไทยโดยเฉพาะ (Large Language Model optimized for Thai) มีความสามารถในการโต้ตอบข้อความภาษาไทยได้อย่างรวดเร็วและหลากหลาย ไม่ว่าจะเป็น การสรุปเนื้อหา การแปลภาษา การระดมสมองคิดไอเดีย การตอบคำถามที่ซับซ้อน และการประมวลผลภาษาไทยอื่นๆ ที่เหมาะสมกับบริบททางสังคมและวัฒนธรรมไทย แถมยังมีประสิทธิภาพเทียบเท่ากับ GPT-3.5 ในภาษาไทย ซึ่งข้อมูลนี้วัดจาก Benchmark ที่รวบรวมและจัดเตรียมมาจากข้อสอบภาษาไทยความยากเทียบเท่าข้อสอบมัธยมปลายและข้อสอบมาตรฐานของผู้ให้คำปรึกษาด้านการเงินในประเทศไทยเลยทีเดียว
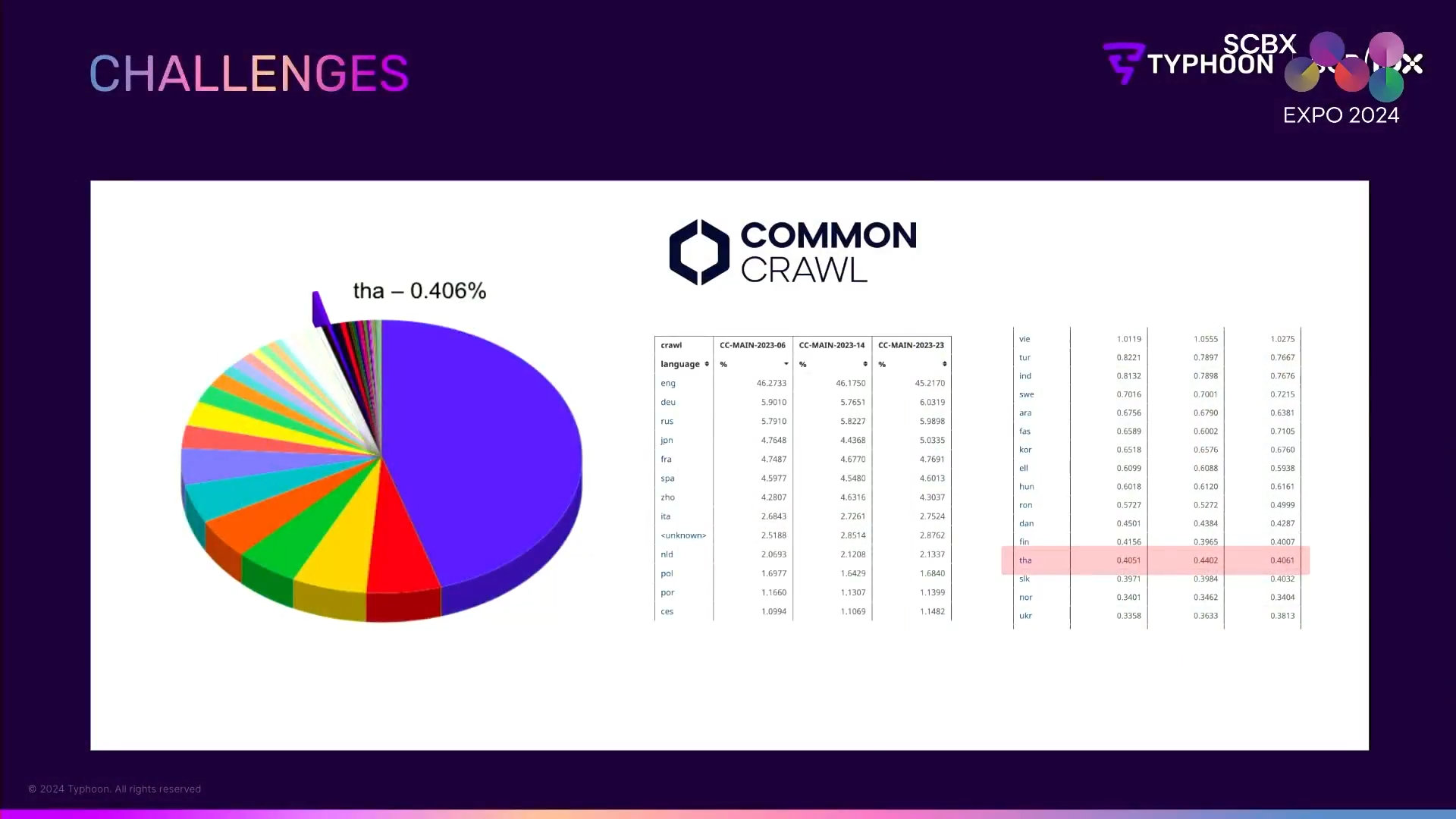
ในงาน SCBX EXPO 2024 คุณกสิมะ ธารพิพิธชัย Head of AI Strategy จาก บริษัท SCB 10X ได้มาแชร์แรงบันดาลใจในการพัฒนา Typhoon ไว้อย่างน่าสนใจ โดยได้ยกประเด็นปัญหาที่คนไทยมักพบเจอเมื่อใช้งานโมเดลภาษาที่พัฒนาโดยชาวต่างชาติ เช่น ถามภาษาไทย แต่ตอบกลับมาเป็นภาษาอังกฤษ หรือตอบเป็นภาษาไทย แต่ไม่ใช่คำตอบในบริบทของคนไทย เป็นต้น นั่นเป็นเพราะโมเดลส่วนใหญ่ถูกฝึกฝนเป็นภาษาอังกฤษเป็นหลัก อีกทั้งภาษาไทยถูกเก็บข้อมูลไว้น้อยมาก โดยข้อมูลจาก Common Crawl ที่มีการเข้าไปเก็บชุดข้อมูล (Dataset) ภาษาต่าง ๆ ทั่วโลก พบว่าชุดข้อมูลภาษาอังกฤษถูกเก็บได้มากถึง 46% ในขณะที่ชุดข้อมูลภาษาไทยเก็บได้เพียง 0.406% ซึ่งน้อยกว่าข้อมูลภาษาอังกฤษกว่าร้อยเท่า ส่งผลให้ประสิทธิภาพ และการพัฒนาต่อยอดการใช้งานที่เป็นภาษาไทยไม่ดีเท่าที่ควร การจะรอให้บริษัทข้ามชาติ กระโดดเข้ามาลงทุนเพื่อโฟกัสการใช้งานภาษาไทยโดยเฉพาะย่อมเป็นไปได้ยาก ต้องเป็นคนไทยเท่านั้นที่เข้าถึง เข้าใจ และสามารถพัฒนาโมเดลภาษาไทยออกมาให้เป็นประโยชน์กับคนไทยได้ดีที่สุด

จุดเด่นของ Typhoon อยู่ที่ความเข้าใจในภาษาไทยได้ดี เพราะทาง SCB 10X มีการเพิ่มชุดข้อมูลภาษาไทยใหม่ๆ เข้าไปฝึกฝนอย่างสม่ำเสมอ ทำให้ Typhoon มีความเข้าใจภาษาไทย และมีประสิทธิภาพในการใช้งานสูงกว่าโมเดลภาษาทั่วไป สามารถตัดข้อความตัวหนังสือให้กลายเป็นหน่วยเล็กๆ ที่โมเดลภาษาใช้ในการประมวลผล (เรียกว่า Token) ได้ดียิ่งขึ้น เช่น หากเป็นโมเดลภาษาทั่วไปที่ไม่เข้าใจภาษาไทยดีพอ จะตัดคำว่า “ภาษา” เป็น 4 หน่วยตามตัวอักษร (“ภ-า-ษ-า”) ในขณะที่ Typhoon จะตัดเป็นคำให้เลย ดังนั้น คำว่า “ภาษา” จะถูกนับเป็นเพียง 1 หน่วย (“ภาษา”) เท่านั้น ส่งผลให้ Typhoon สามารถประหยัดจำนวน token เมื่อประมวลผลภาษาไทยได้มากกว่า GPT-4 ถึง 2.62 เท่า และให้ผลลัพธ์ออกมาถูกต้อง ครบถ้วน และตรงใจคนไทยมากกว่า
การเกิดขึ้นของ Typhoon มีบทบาทสำคัญอย่างมากในการช่วยลดช่องว่างทางภาษา รวมถึงข้อจำกัดด้านทรัพยากรของภาษาไทยที่ไม่มีข้อมูลมากเพียงพอ (Low Resource Language) โดยทีมงาน SCB 10X ได้พัฒนาโมเดลภาษาไทยภายใต้ชื่อ “Typhoon” แบบ End to End ตั้งแต่กระบวนการทำชุดข้อมูลภาษาไทย (Dataset), การพัฒนาโมเดล (Model Development), การวางโครงสร้าง (Infrastructure) และ การพัฒนา Application แต่ละกระบวนการจะทำงานร่วมกับผู้เชี่ยวชาญด้านต่างๆ เช่น Stanford HAI, Percy Liang, VISTEC และ InnovestX เป็นต้น

ล่าสุดทีม SCB 10X ได้อัปเกรด Typhoon ให้เป็นเวอร์ชัน “Typhoon 1.5X” ที่สามารถแข่งขันในด้านการทำงานตามคำสั่งและการใช้งานจริงเทียบกับรุ่นใหญ่อย่าง GPT-3.5-turbo และ GPT-4-0612 ได้อย่างสูสี
Typhoon 1.5X เป็นโมเดลเชิงทดลอง (eXperimental Model) ที่ออกแบบมาเพื่อเน้นการใช้งานจริงบนแอปพลิเคชันที่หลากหลาย สามารถเข้าใจความต้องการของผู้ใช้และนำเสนอคำตอบที่ตรงประเด็นมากขึ้นสามารถทำงานที่ซับซ้อนได้ดียิ่งขึ้น ต่อยอดจากโมเดลรุ่นก่อนหน้าที่โดดเด่นในความรู้ด้านภาษาไทย มีโมเดลที่ใหญ่ขึ้นและมีประสิทธิภาพมากขึ้น โดยมี 2 ขนาด ได้แก่ โมเดล “Typhoon-1.5X 8B” ที่มีค่าพารามิเตอร์ 8 พันล้าน และ “Typhoon-1.5X 70B” ที่มีค่าพารามิเตอร์ 70 พันล้านหน่วย ช่วยเพิ่มศักยภาพความแม่นยำและความกว้างขวางของข้อมูล ความรู้ความสามารถด้านภาษา ไปจนถึงประสิทธิภาพในการทำตามคำสั่งและเข้าใจภาษามนุษย์ที่ดีขึ้นในภาษาไทย ประเมินโดยใช้ชุดข้อมูลคำถามปรนัยภาษาไทยและข้อสอบสำหรับ Generative AI เช่น ThaiExam และ MMLU (Massive Multitask Language Understanding) นอกจากนี้ ยังมีการนำเทคนิคต่างๆ เช่น “Retrieval-Augmented Generation (RAG)” เข้ามาเสริม เพื่อให้ Typhoon สามารถนำไปใช้ในทางธุรกิจได้ดียิ่งขึ้น
Typhoon 1.5X ถูกพัฒนาให้เพิ่มขีดความสามารถในการทำงานตามคำสั่ง ประเมินโดยอาศัย Feedback จากการทดลองใช้จริง ซึ่งมุ่งเน้น 2 ปัจจัยหลัก คือ 1. ความเข้าใจผู้ใช้และการใช้เหตุผลของมนุษย์ (ประเมินโดยใช้ MT-Bench) และ 2. การทำงานตามคำสั่งตามข้อจำกัดที่ระบุ (ประเมินโดยใช้ IFEval)
ผู้ใช้สามารถมั่นใจในประสิทธิภาพที่สูงขึ้นอีกขั้น ด้วยความสามารถในการดำเนินงานด้วยตัวเองของ AI (Agentic Capabilities) ที่ได้รับการประเมินผ่าน Hugging Face’s Transformer Agents และชุดเกณฑ์มาตรฐานที่เกี่ยวข้อง
ขอบคุณทีม SCB 10X ที่เข้ามาช่วยขับเคลื่อนเทคโนโลยี AI ของไทยให้มี Ecosystem และ Community ในการพัฒนาโมเดลภาษาไทยขนาดใหญ่เป็นของเราเอง มี Open Source AI ที่เข้าใจภาษา วัฒนธรรม และความต้องการของคนไทยได้อย่างมีประสิทธิภาพ อีกทั้งยังช่วยเพิ่มศักยภาพด้านการแข่งขันในอุตสาหกรรม AI ของคนไทยเราอีกด้วย
ที่มา: งานสัมมนา SCBX AI EXPO 2024 หัวข้อ “Pushing Boundaries in Thai AI: Unleashing Typhoon for Superior Language Understanding and Human Alignment” โดยคุณกสิมะ ธารพิพิธชัย Head of AI Strategy จาก บริษัท SCB 10X